



Processing Geospatial Data at Scale With Databricks
This blog was written 3 years ago. Please refer to these articles for up-to-date approaches to geospatial processing and analytics with your Databricks...
This blog was written 3 years ago. Please refer to these articles for up-to-date approaches to geospatial processing and analytics with your Databricks Lakehouse:
The evolution and convergence of technology has fueled a vibrant marketplace for timely and accurate geospatial data. Every day billions of handheld and IoT devices along with thousands of airborne and satellite remote sensing platforms generate hundreds of exabytes of location-aware data. This boom of geospatial big data combined with advancements in machine learning is enabling organizations across industry to build new products and capabilities.
For example, numerous companies provide localized drone-based services such as mapping and site inspection (reference Developing for the Intelligent Cloud and Intelligent Edge). Another rapidly growing industry for geospatial data is autonomous vehicles. Startups and established companies alike are amassing large corpuses of highly contextualized geodata from vehicle sensors to deliver the next innovation in self-driving cars (reference Databricks fuels wejo's ambition to create a mobility data ecosystem). Retailers and government agencies are also looking to make use of their geospatial data. For example, foot-traffic analysis (reference Building Foot-Traffic Insights Dataset) can help determine the best location to open a new store or, in the Public Sector, improve urban planning. Despite all these investments in geospatial data, a number of challenges exist.
The first challenge involves dealing with scale in streaming and batch applications. The sheer proliferation of geospatial data and the SLAs required by applications overwhelms traditional storage and processing systems. Customer data has been spilling out of existing vertically scaled geo databases into data lakes for many years now due to pressures such as data volume, velocity, storage cost, and strict schema-on-write enforcement. While enterprises have invested in geospatial data, few have the proper technology architecture to prepare these large, complex datasets for downstream analytics. Further, given that scaled data is often required for advanced use cases, the majority of AI-driven initiatives are failing to make it from pilot to production.
Compatibility with various spatial formats poses the second challenge. There are many different specialized geospatial formats established over many decades as well as incidental data sources in which location information may be harvested:
In this blog post, we give an overview of general approaches to deal with the two main challenges listed above using the Databricks Unified Data Analytics Platform. This is the first part of a series of blog posts on working with large volumes of geospatial data.
Databricks offers a unified data analytics platform for big data analytics and machine learning used by thousands of customers worldwide. It is powered by Apache Spark™, Delta Lake, and MLflow with a wide ecosystem of third-party and available library integrations. Databricks UDAP delivers enterprise-grade security, support, reliability, and performance at scale for production workloads. Geospatial workloads are typically complex and there is no one library fitting all use cases. While Apache Spark does not offer geospatial Data Types natively, the open source community as well as enterprises have directed much effort to develop spatial libraries, resulting in a sea of options from which to choose.
There are generally three patterns for scaling geospatial operations such as spatial joins or nearest neighbors:
The examples which follow are generally oriented around a NYC taxi pickup / dropoff dataset found here. NYC Taxi Zone data with geometries will also be used as the set of polygons. This data contains polygons for the five boroughs of NYC as well the neighborhoods. This notebook will walk you through preparations and cleanings done to convert the initial CSV files into Delta Lake Tables as a reliable and performant data source.
Our base DataFrame is the taxi pickup / dropoff data read from a Delta Lake Table using Databricks.
%scala
val dfRaw = spark.read.format("delta").load("/ml/blogs/geospatial/delta/nyc-green")
display(dfRaw) // showing first 10 columns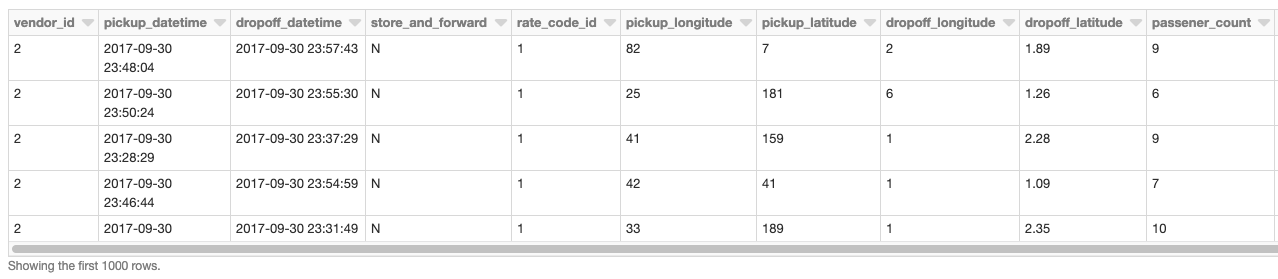
Over the last few years, several libraries have been developed to extend the capabilities of Apache Spark for geospatial analysis. These frameworks bear the brunt of registering commonly applied user defined types (UDT) and functions (UDF) in a consistent manner, lifting the burden otherwise placed on users and teams to write ad-hoc spatial logic. Please note that in this blog post we use several different spatial frameworks chosen to highlight various capabilities. We understand that other frameworks exist beyond those highlighted which you might also want to use with Databricks to process your spatial workloads.
Earlier, we loaded our base data into a DataFrame. Now we need to turn the latitude/longitude attributes into point geometries. To accomplish this, we will use UDFs to perform operations on DataFrames in a distributed fashion. Please refer to the provided notebooks at the end of the blog for details on adding these frameworks to a cluster and the initialization calls to register UDFs and UDTs. For starters, we have added GeoMesa to our cluster, a framework especially adept at handling vector data. For ingestion, we are mainly leveraging its integration of JTS with Spark SQL which allows us to easily convert to and use registered JTS geometry classes. We will be using the function st_makePoint that given a latitude and longitude create a Point geometry object. Since the function is a UDF, we can apply it to columns directly.
%scala
val df = dfRaw
.withColumn("pickup_point", st_makePoint(col("pickup_longitude"), col("pickup_latitude")))
.withColumn("dropoff_point", st_makePoint(col("dropoff_longitude"),col("dropoff_latitude")))
display(df.select("dropoff_point","dropoff_datetime"))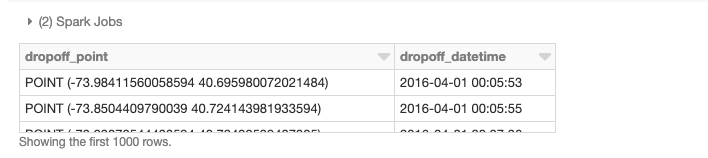
We can also perform distributed spatial joins, in this case using GeoMesa's provided st_contains UDF to produce the resulting join of all polygons against pickup points.
%scala
val joinedDF = wktDF.join(df, st_contains($"the_geom", $"pickup_point")
display(joinedDF.select("zone","borough","pickup_point","pickup_datetime"))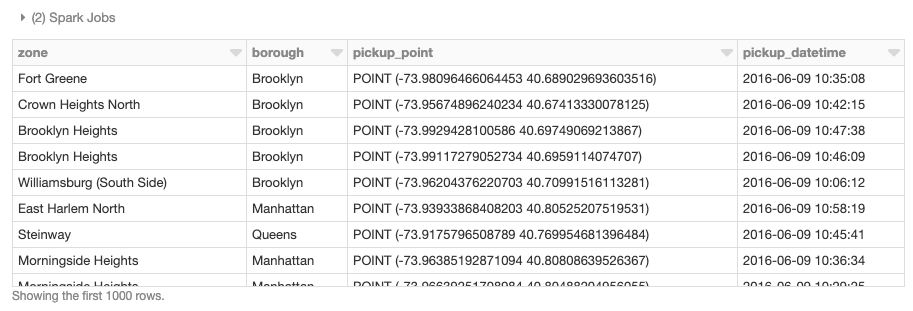
In addition to using purpose built distributed spatial frameworks, existing single-node libraries can also be wrapped in ad-hoc UDFs for performing geospatial operations on DataFrames in a distributed fashion. This pattern is available to all Spark language bindings – Scala, Java, Python, R, and SQL – and is a simple approach for leveraging existing workloads with minimal code changes. To demonstrate a single-node example, let's load NYC borough data and define UDF find_borough(...) for point-in-polygon operation to assign each GPS location to a borough using geopandas. This could also have been accomplished with a vectorized UDF for even better performance.
%python
# read the boroughs polygons with geopandas
gdf = gdp.read_file("/dbfs/ml/blogs/geospatial/nyc_boroughs.geojson")
b_gdf = sc.broadcast(gdf) # broadcast the geopandas dataframe to all nodes of the cluster
def find_borough(latitude,longitude):
mgdf = b_gdf.value.apply(lambda x: x["boro_name"] if x["geometry"].intersects(Point(longitude, latitude))
idx = mgdf.first_valid_index()
return mgdf.loc[idx] if idx is not None else None
find_borough_udf = udf(find_borough, StringType())Now we can apply the UDF to add a column to our Spark DataFrame which assigns a borough name to each pickup point.
%python
# read the coordinates from delta
df = spark.read.format("delta").load("/ml/blogs/geospatial/delta/nyc-green")
df_with_boroughs = df.withColumn("pickup_borough", find_borough_udf(col("pickup_latitude"),col(pickup_longitude)))
display(df_with_boroughs.select(
"pickup_datetime","pickup_latitude","pickup_longitude","pickup_borough"))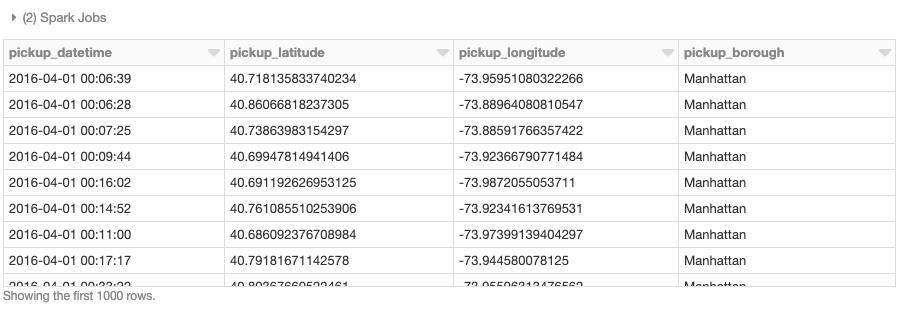
Geospatial operations are inherently computationally expensive. Point-in-polygon, spatial joins, nearest neighbor or snapping to routes all involve complex operations. By indexing with grid systems, the aim is to avoid geospatial operations altogether. This approach leads to the most scalable implementations with the caveat of approximate operations. Here is a brief example with H3.
Scaling spatial operations with H3 is essentially a two step process. The first step is to compute an H3 index for each feature (points, polygons, …) defined as UDF geoToH3(...). The second step is to use these indices for spatial operations such as spatial join (point in polygon, k-nearest neighbors, etc), in this case defined as UDF multiPolygonToH3(...).
%scala
import com.uber.h3core.H3Core
import com.uber.h3core.util.GeoCoord
import scala.collection.JavaConversions._
import scala.collection.JavaConverters._
object H3 extends Serializable {
val instance = H3Core.newInstance()
}
val geoToH3 = udf{ (latitude: Double, longitude: Double, resolution: Int) =>
H3.instance.geoToH3(latitude, longitude, resolution)
}
val polygonToH3 = udf{ (geometry: Geometry, resolution: Int) =>
var points: List[GeoCoord] = List()
var holes: List[java.util.List[GeoCoord]] = List()
if (geometry.getGeometryType == "Polygon") {
points = List(
geometry
.getCoordinates()
.toList
.map(coord => new GeoCoord(coord.y, coord.x)): _*)
}
H3.instance.polyfill(points, holes.asJava, resolution).toList
}
val multiPolygonToH3 = udf{ (geometry: Geometry, resolution: Int) =>
var points: List[GeoCoord] = List()
var holes: List[java.util.List[GeoCoord]] = List()
if (geometry.getGeometryType == "MultiPolygon") {
val numGeometries = geometry.getNumGeometries()
if (numGeometries > 0) {
points = List(
geometry
.getGeometryN(0)
.getCoordinates()
.toList
.map(coord => new GeoCoord(coord.y, coord.x)): _*)
}
if (numGeometries > 1) {
holes = (1 to (numGeometries - 1)).toList.map(n => {
List(
geometry
.getGeometryN(n)
.getCoordinates()
.toList
.map(coord => new GeoCoord(coord.y, coord.x)): _*).asJava
})
}
}
H3.instance.polyfill(points, holes.asJava, resolution).toList
}We can now apply these two UDFs to the NYC taxi data as well as the set of borough polygons to generate the H3 index.
%scala
val res = 7 //the resolution of the H3 index, 1.2km
val dfH3 = df.withColumn(
"h3index",
geoToH3(col("pickup_latitude"), col("pickup_longitude"), lit(res))
)
val wktDFH3 = wktDF
.withColumn("h3index", multiPolygonToH3(col("the_geom"), lit(res)))
.withColumn("h3index", explode($"h3index"))Given a set of a lat/lon points and a set of polygon geometries, it is now possible to perform the spatial join using h3index field as the join condition. These assignments can be used to aggregate the number of points that fall within each polygon for instance. There are usually millions or billions of points that have to be matched to thousands or millions of polygons which necessitates a scalable approach. There are other techniques not covered in this blog which can be used for indexing in support of spatial operations when an approximation is insufficient.
%scala
val dfWithBoroughH3 = dfH3.join(wktDFH3,"h3index")
display(df_with_borough_h3.select("zone","borough","pickup_point","pickup_datetime","h3index"))
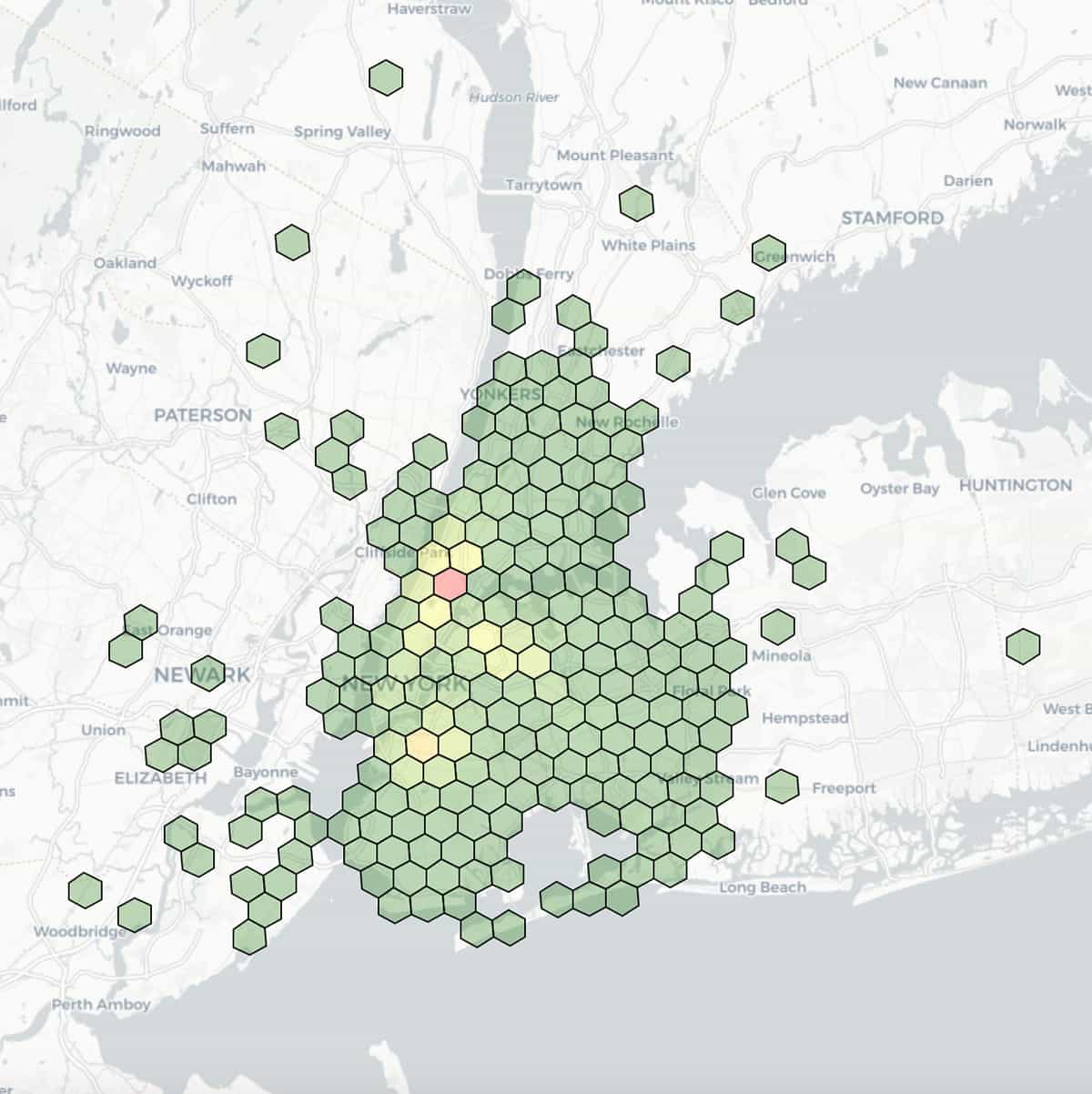
Here is a visualization of taxi dropoff locations, with latitude and longitude binned at a resolution of 7 (1.22km edge length) and colored by aggregated counts within each bin.
Geospatial data involves reference points, such as latitude and longitude, to physical locations or extents on the earth along with features described by attributes. While there are many file formats to choose from, we have picked out a handful of representative vector and raster formats to demonstrate reading with Databricks.
Vector data is a representation of the world stored in x (longitude), y (latitude) coordinates in degrees, also z (altitude in meters) if elevation is considered. The three basic symbol types for vector data are points, lines, and polygons. Well-known-text (WKT), GeoJSON, and Shapefile are some popular formats for storing vector data we highlight below.
Let's read NYC Taxi Zone data with geometries stored as WKT. The data structure we want to get back is a DataFrame which will allow us to standardize with other APIs and available data sources, such as those used elsewhere in the blog. We are able to easily convert the WKT text content found in field the_geom into its corresponding JTS Geometry class through the st_geomFromWKT(...) UDF call.
%scala
val wktDFText = sqlContext.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/ml/blogs/geospatial/nyc_taxi_zones.wkt.csv")
val wktDF = wktDFText.withColumn("the_geom", st_geomFromWKT(col("the_geom"))).cacheGeoJSON is used by many open source GIS packages for encoding a variety of geographic data structures, including their features, properties, and spatial extents. For this example, we will read NYC Borough Boundaries with the approach taken depending on the workflow. Since the data is conforming JSON, we could use the Databricks built-in JSON reader with .option("multiline","true") to load the data with the nested schema.
%python
json_df = spark.read.option("multiline","true").json("nyc_boroughs.geojson")
From there we could choose to hoist any of the fields up to top level columns using Spark's built-in explode function. For example, we might want to bring up geometry, properties, and type and then convert geometry to its corresponding JTS class as was shown with the WKT example.
%python
from pyspark.sql import functions as F
json_explode_df = ( json_df.select(
"features",
"type",
F.explode(F.col("features.properties")).alias("properties")
).select("*",F.explode(F.col("features.geometry")).alias("geometry")).drop("features"))
display(json_explode_df)
We can also visualize the NYC Taxi Zone data within a notebook using an existing DataFrame or directly rendering the data with a library such as Folium, a Python library for rendering spatial data. Databricks File System (DBFS) runs over a distributed storage layer which allows code to work with data formats using familiar file system standards. DBFS has a FUSE Mount to allow local API calls which perform file read and write operations,which makes it very easy to load data with non-distributed APIs for interactive rendering. In the Python open(...) command below, the "/dbfs/..." prefix enables the use of FUSE Mount.
%python
import folium
import json
with open ("/dbfs/ml/blogs/geospatial/nyc_boroughs.geojson", "r") as myfile:
boro_data=myfile.read() # read GeoJSON from DBFS using FuseMount
m = folium.Map(
location=[40.7128, -74.0060],
tiles='Stamen Terrain',
zoom_start=12
)
folium.GeoJson(json.loads(boro_data)).add_to(m)
m # to display, also could use displayHTML(...) variants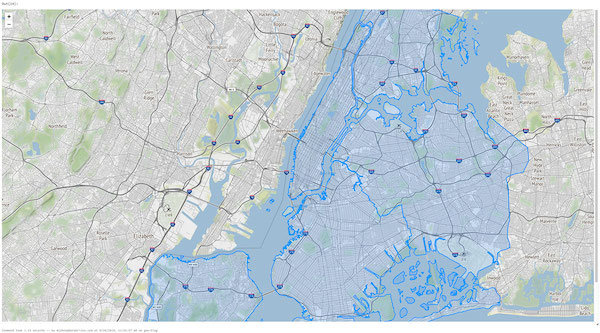
Shapefile is a popular vector format developed by ESRI which stores the geometric location and attribute information of geographic features. The format consists of a collection of files with a common filename prefix (*.shp, *.shx, and *.dbf are mandatory) stored in the same directory. An alternative to shapefile is KML, also used by our customers but not shown for brevity. For this example, let's use NYC Building shapefiles. While there are many ways to demonstrate reading shapefiles, we will give an example using GeoSpark. The built-in ShapefileReader is used to generate the rawSpatialDf DataFrame.
%scala
var spatialRDD = new SpatialRDD[Geometry]
spatialRDD = ShapefileReader.readToGeometryRDD(sc, "/ml/blogs/geospatial/shapefiles/nyc")
var rawSpatialDf = Adapter.toDf(spatialRDD,spark)
rawSpatialDf.createOrReplaceTempView("rawSpatialDf") //DataFrame now available to SQL, Python, and R By registering rawSpatialDf as a temp view, we can easily drop into pure Spark SQL syntax to work with the DataFrame, to include applying a UDF to convert the shapefile WKT into Geometry.
%sql
SELECT *,
ST_GeomFromWKT(geometry) AS geometry -- GeoSpark UDF to convert WKT to Geometry
FROM rawspatialdf Additionally, we can use Databricks built in visualization for inline analytics such as charting the tallest buildings in NYC.
%sql
SELECT name,
round(Cast(num_floors AS DOUBLE), 0) AS num_floors --String to Number
FROM rawspatialdf
WHERE name ''
ORDER BY num_floors DESC LIMIT 5
Raster data stores information of features in a matrix of cells (or pixels) organized into rows and columns (either discrete or continuous). Satellite images, photogrammetry, and scanned maps are all types of raster-based Earth Observation (EO) data.
The following Python example uses RasterFrames, a DataFrame-centric spatial analytics framework, to read two bands of GeoTIFF Landsat-8 imagery (red and near-infrared) and combine them into Normalized Difference Vegetation Index. We can use this data to assess plant health around NYC. The rf_ipython module is used to manipulate RasterFrame contents into a variety of visually useful forms, such as below where the red, NIR and NDVI tile columns are rendered with color ramps, using the Databricks built-in displayHTML(...) command to show the results within the notebook.
%python
# construct a CSV "catalog" for RasterFrames `raster` reader
# catalogs can also be Spark or 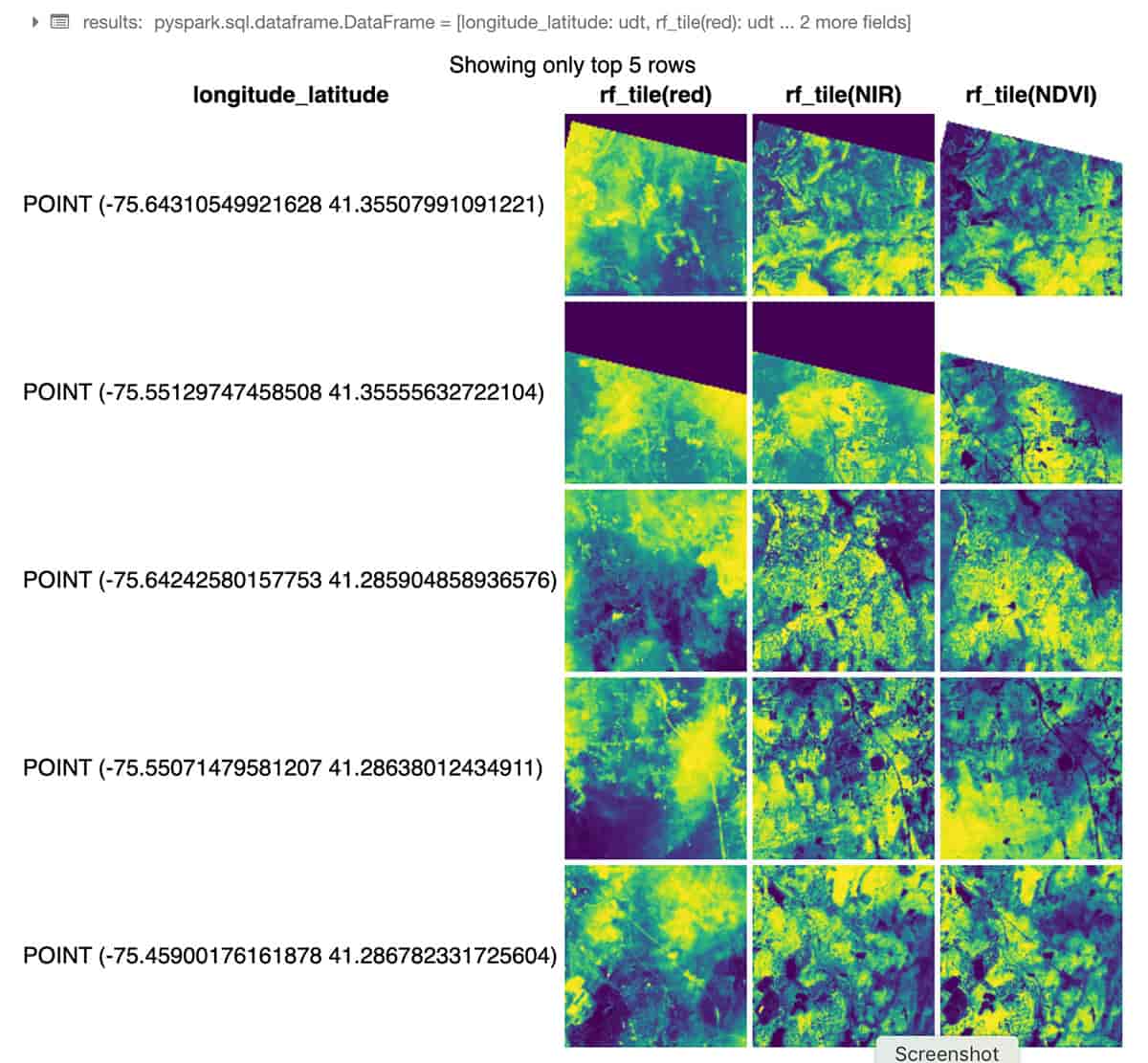
Through its custom Spark DataSource, RasterFrames can read various raster formats, including GeoTIFF, JP2000, MRF, and HDF, from an array of services. It also supports reading the vector formats GeoJSON and WKT/WKB. RasterFrame contents can be filtered, transformed, summarized, resampled, and rasterized through 200+ raster and vector functions, such as st_reproject(...) and st_centroid(...) used in the example above. It provides APIs for Python, SQL, and Scala as well as interoperability with Spark ML.
Geo databases can be filebased for smaller scale data or accessible via JDBC / ODBC connections for medium scale data. You can use Databricks to query many SQL databases with the built-in JDBC / ODBC Data Source. Connecting to PostgreSQL is shown below which is commonly used for smaller scale workloads by applying PostGIS extensions. This pattern of connectivity allows customers to maintain as-is access to existing databases.
%scala
display(
sqlContext.read.format("jdbc")
.option("url", jdbcUrl)
.option("driver", "org.postgresql.Driver")
.option("dbtable",
"""(SELECT * FROM yellow_tripdata_staging
OFFSET 5 LIMIT 10) AS t""") //predicate pushdown
.option("user", jdbcUsername)
.option("jdbcPassword", jdbcPassword)
.load)
Businesses and government agencies seek to use spatially referenced data in conjunction with enterprise data sources to draw actionable insights and deliver on a broad range of innovative use cases. In this blog we demonstrated how the Databricks Unified Data Analytics Platform can easily scale geospatial workloads, enabling our customers to harness the power of the cloud to capture, store and analyze data of massive size.
In an upcoming blog, we will take a deep dive into more advanced topics for geospatial processing at-scale with Databricks. You will find additional details about the spatial formats and highlighted frameworks by reviewing Data Prep Notebook, GeoMesa + H3 Notebook, GeoSpark Notebook, GeoPandas Notebook, and Rasterframes Notebook. Also, stay tuned for a new section in our documentation specifically for geospatial topics of interest.